Ormai anche i muri sanno che le connessioni https sono da preferire a quelle http, le connessioni imaps a quelle imap (143/TCP) o le connessioni submission SSL/TLS sono da preferire a quelle smtp (25/TCP) qualora ci si autentifichi per inviare email.
Questo è assodato, ma la domanda che spesso mi rivolgono è "ok, ma chi vuoi abbia mai le competenze per catturare le mie password?". Proviamo a fare un laboratorio per cercare di capire quanto è semplice.
Come in linea con il resto del blog, in questo articolo non verrà spiegato come fare, lo scopo esclusivo è quello di sensibilizzare alla sicurezza informatica.
L'articolo è rivolto sia ai normali utilizzatori, sia a chi ha a che fare con queste tecnologie e spesso per "pigrizia" o per mancanza di volontà preferisce configurare connessioni in chiaro piuttosto che seguire la strada corretta di dotare ed utilizzare sul proprio server un certificato valido.
Hardware
Per questa prima prova, inizieremo a fare un Man in The Middle (MiTM) su una connessione ethernet, interrompendo in maniera silente ed invisibile un collegamento fisico.

Nello specifico, banalmente ci siamo dotati di una qualsiasi macchina con 2 schede di rete, intercettando una patch.


Più "in alto" intercettiamo la patch, e più informazioni carpiamo. Se intercettiamo la patch del router, è evidente che avremo informazioni riguardanti l'intera rete, se intercettiamo solo quella di un host, la nostra ricerca si limiterà a quest'ultimo ed al traffico di broadcast.
Lo stesso ragionamento vale in ambito geografico, ricordandoci che internet è un insieme di nodi e rimbalzi da un punto "A" ad un punto "B" e nel mezzo attraversiamo potenzialmente decine di scenari in cui questa operazione di sniffing è facilmente fattibile.
Software
Come sistema operativo abbiamo utilizzato una distribuzione Linux specifica e normalmente utilizzata per questo tipo di attività, tuttavia avremmo potuto fare la medesima cosa con una distribuzione qualsiasi e persino con una macchina Windows con uno sniffer di rete attivo. L'aver utilizzato una distribuzione specifica ci ha solo velocizzato le operazioni di installazione dei tool, facilmente reperibili in rete.
Questa è sostanzialmente la cronologia delle operazioni, con relativo tempo impiegato.
- Scaricamento ed installazione della distribuzione Linux (40m)
- Configurazione del bridge tra eth2 ed eth4, le nostre NIC (10m)
- Esecuzione e configurazione dei tool di sniffing e logging delle password (5m)

I risultati
Nel giro di meno di 1h abbiamo creato una macchina in grado di catturare tutto il traffico e restituirci le credenziali di accesso in chiaro.

Qui sopra possiamo osservare il risultato di un test di login su un form di autenticazione in HTTP e di un'interrogazione IMAP su di un qualsiasi server di posta. Facile, no?
Access Point liberi
Facciamo un passo in avanti. Per catturare quelle informazioni abbiamo bisogno indubbiamente di un accesso fisico. Potrebbe essere più semplice, quindi, lasciare un simpatico Access Point aperto a tutti.
Ed ecco che:
- Installeremo e configureremo il sistema di emulazione AP (15m)
- Creeremo le regole di NAT dalla (nel nostro caso) wlan2 alla br0 (5m)
- Installeremo e configureremo un Server DHCP per rilasciare gli indirizzi alla wlan (15m)


E come una carta moschicida, in un attimo avremo il traffico (e quindi le relative password) di chi vi si connette, dando in cambio un po' di banda.
Spiegato, concretamente, uno degli evergreen della sicurezza "user-side": mai connettersi a reti non affidabili o aperte. Il rischio di incappare in reti volontariamente lasciate aperte per raccogliere dati è altissimo.
Proxy SSL
Spostiamoci ancora più in là. Creiamo un proxy al cui interno fare decrypt del traffico crittografato. Il funzionamento è pressappoco questo (agiremo creando delle semplici regole di NAT in grado di intercettare le porte su cui il traffico non in chiaro tradizionalmente avviene):

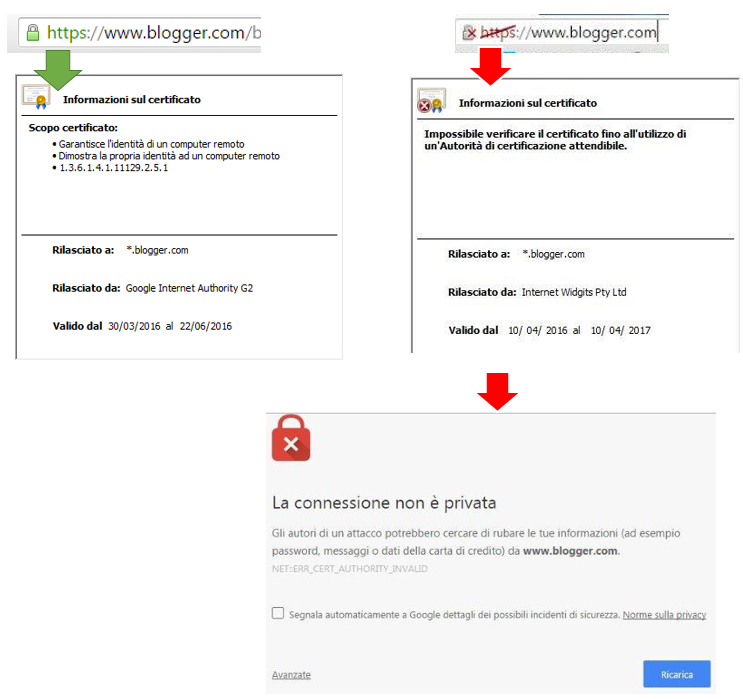
L'utente, come spesso accade, avrà una richiesta di accettazione di un certificato (a sinistra una connessione sicura, a destra una alterata). E' evidente che qualsiasi proxy deve necessariamente riscrivere il traffico, quindi il massimo che si può fare è generare un certificato per la porzione di traffico Proxy-Client.
All'interno del proxy SSL, quindi, vi è una generazione di un certificato forgiato ad hoc per la sessione, ed ogni sessione ha il suo certificato creato in real time con lo scopo di ingannare l'utente.
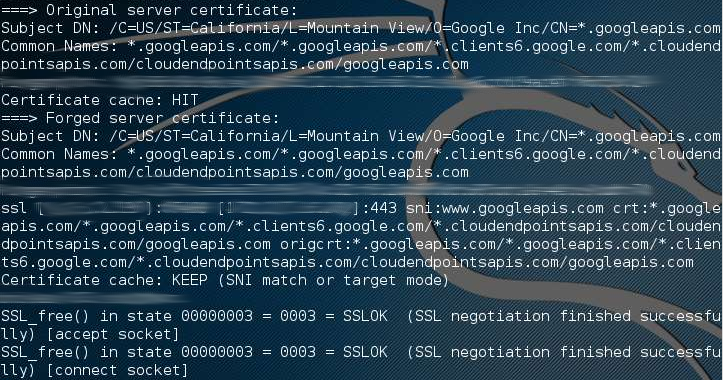
Sostanzialmente tutto il traffico originariamente crittografato, diviene in chiaro, esponendoci ai rischi di cui sopra.
Ed eccoci al secondo evergreen informatico: "non accettare mai tutti i certificati, ovvero non cliccare sempre e solamente su continua".
NB: Se si importa la root CA del proxy, e quindi l'attaccante ha accesso alla macchina client, i certificati vengono visti come verdi!
More, more and more...
Non ci siamo spinti oltre, non abbiamo parlato di arp poisoning con lo scopo di dirottare il traffico verso di noi al posto del gateway (magari lo faremo in un prossimo articolo), non abbiamo parlato di DoS su WiFi con lo scopo di sostituirsi ad un Access Point, non abbiamo parlato di fake web page con lo scopo di fare injection di codice malevolo... insomma... c'è tanta carne sul fuoco già in questo articolo.
Le morali della favola sono:
- Evitare come fosse peste bubbonica le connessioni in chiaro (se un sito è HTTP, inserire credenziali non è mai una buona idea)
- Quando un certificato https è "rosso", c'è un motivo. E se il browser vi segnala un problema, tenetene conto.




